-
 2022.04.29
2022.04.2917314
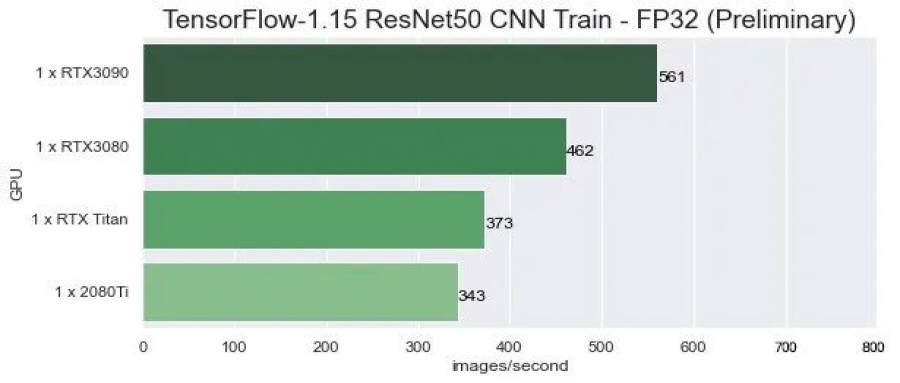
RTX 3090深度学习性能实测奉上!模型训练可提升40~60%
RTX 3090在深度学习训练任务中,性能表现究竟如何,它能否取代Titan RTX成为最强消费级AI训练卡?现在已经有了答案。如果需要搭建128块以上的GPU集群,8块成组的Tesla A100显然效率更高;如果超过512块GPU,则推荐使用DGX A100系统。目前RTX 3090更适合于高校、科研单位、企业的模型训练应用,性价比高、部署快、模型训练效率提升可实现40%~60%!...
查看全文 -
 2022.04.28
2022.04.282463
国产cpu厂商概览,Cloudhin云轩支持深度学习服务器国产化定制
CPU作为计算机设备的运算和控制核心,负责指令读取、译码与执行,因研发门槛高、生态构建难,被认为是集成电路产业中的“珠穆朗玛峰”。纵观全球,Intel、AMD两大巨头领跑通用CPU市场;国内,国产CPU正处于奋力追赶的关键时期,以鲲鹏、海光、龙芯、飞腾、申威等为代表的厂商正全力打造“中国芯”。...
查看全文 -
 2022.04.28
2022.04.282338
【小巧强劲】PCIE版安培计算卡亮相,更适合高性能计算服务器定制
NVIDIA A100 Tensor Core GPU可针对AI、数据分析和高性能计算(HPC),在各种规模上实现出色的加速,应对极其严峻的计算挑战。前不久,基于标准PCIe形态的A100计算卡也终于登场了,更适合主流标准服务器。我们详细对比了两种不同形态的A100,一起来看看区别吧。...
查看全文 -
 2022.04.27
2022.04.272034
显卡选择-专业图形显卡对比游戏显卡,3个不同点很关键
很多人觉得专业显卡售价实在太贵,买专业显卡还不如买一块高端游戏显卡,做工精良的游戏显卡至少看上去“威武”多了,性能“应该”不会差。实际上,虽然在硬件方面专业显卡和游戏显卡完全相同,但软件应用方面的差别导致两者的定位泾渭分明。...
查看全文
